


The biggest advantage of a WYSIWYG is apparent in its name. It shows the writer what their content looks like as they’re typing it, allowing them to simultaneously write and design the text. That single attribute makes content creators' lives so much easier.
To achieve this wonder, the HTML code that supports the process, requires different kinds of attributes to be added to each tag. This includes style tags, class tags, id tags, href tags, and label tags… That’s a not insignificant amount of additional information to handle!
TinyMCE’s WYSIWYG has several options to get and receive HTML content (usually in the form of a string). If you’ve set up a get content function, and you’re waiting to get content back, it’s possible to remove style or other tags, and clear the content when it arrives at the destination you set up.
There are a few methods to do this – one of them involves regular expressions.
Be aware that regular expressions can remove style, along with all kinds of other HTML attributes as well, which can damage the HTML output. In short, it is easy to set up, but difficult to refine.
There are also edge case issues to consider. There may be different HTML attributes that a regular expression cannot parse and report back on. You can remove attributes, style tags, and other HTML tag contents with TinyMCE APIs as an alternative, which can help avoid edge cases and clearing away necessary attributes you want to keep.
If you'd like to try a regex solution, and it fits your use case, that’s what this article explains. It covers getting HTML content back from TinyMCE through the TinyMCE API, and how to remove tag content attributes like style and class.
What are regular expressions?
Regular expressions are a sequence of specific characters used for targeted search and replace operations. What makes regular expressions useful, especially to remove style or clear content, is that they can target specific words and characters around those words. The information returned by the regular expression (also called regex) search can then be used to change content.
While they can search and parse for text and characters, regular expressions have limits. They can detect a style tag, but their search range may continue to pick up and collect other HTML attributes. It's important to consider how they will affect the actual HTML attributes used in production.
Getting HTML from TinyMCE
TinyMCE’s APIs offer the main methods to get content, and remove style from the content with regular expressions or other means.
|
Method |
How it works |
tinymce.Editor - getContent() |
tinymce.activeEditor.getContent({ format: 'text' }); |
|
tinymce.html.Writer - getContentAreaContainer() |
getContent(): String |
|
tinymce.dom.Selection - getContent() |
getContent(args: Object): String |
The tinymce.activeEditor.getContent is a common and reliable method to get content from TinyMCE.
How to remove attributes from TinyMCE HTML
TinyMCE APIs you can use to for filtering and clearing attributes instead of regex include:
- The TinyMCE DOM Parser API method – addAttributeFilter
- The TinyMCE Dom Serializer API method – addAttributeFilter
There is also the addNodeFilter() method available. These methods parse or serialize the DOM. The attribute filter can detect the specific attribute cases you wish to check and remove. For instance, you could run a sequence of events on your HTML content:
- Set the HTML content
- Run the DOM Parser API, adding an attribute filter
- serialize the HTML
- Output a string and print it to a location.
A full demo is beyond this article's scope, however. The following demo shows an example using a regular expression to quickly remove attributes, being aware of the edge case issues methioned earlier. The demo has a core TinyMCE set with some HTML content, and uses a JavaScript function with a regular expression.
Set up TinyMCE
-
Start by getting a TinyMCE API key. Navigate to the get-tiny page, and once logged in, your API key appears at the top of your dashboard
-
Create a new index.html file on your developer workstation
-
Add the following HTML to get the file started:
<!doctype html>
<html>
<head>
<title>Remove attributes from TinyMCE content</title>
</head>
<body>
</body>
</html>-
Include the TinyMCE Cloud CDN script and init script:
<script src="https://cdn.tiny.cloud/1/qagffr3pkuv17a8on1afax661irst1hbr4e6tbv888sz91jc/tinymce/6/tinymce.min.js" referrerpolicy="origin"></script>
<script>
tinymce.init({selector: '#editor'});
</script>-
Save the changes
Include style and additional functionality
-
Add a button element to the page between the TinyMCE textarea and the div, and give the button an id:
<body>
<textarea id="editor">
<p style="color: blue;">This text has a style attribute.</p>
</textarea>
<button id='buttonRemove' class="button_style">Remove Attributes</button>
<div id="newArea"></div>
</body>-
It’s entirely optional, but you can add some style content to the HTML head to change the button appearance:
<style>
.button_style {
background: #0c132c;
border: azure;
color: #fff;
font-size: 0.75rem;
font-weight: 600;
letter-spacing: 0.1px;
height: 3.5rem;
width: 200px;
}
</style>-
Save the changes
How to set up the JavaScript .replace() method
-
Create a script at the end of the HTML file after the closing body tag, and set up a function for cleaning the TinyMCE content.
This function is going to do the following:-
Get the content from the TinyMCE editor
-
Use a regular expression to detect and remove the style tag with the JavaScript .replace() method
-
Add the content to a new div on the page
-
<script>
function cleanTinyMCEContent() {-
Start with the getContent() method:
<script>
function cleanTinyMCEContent() {
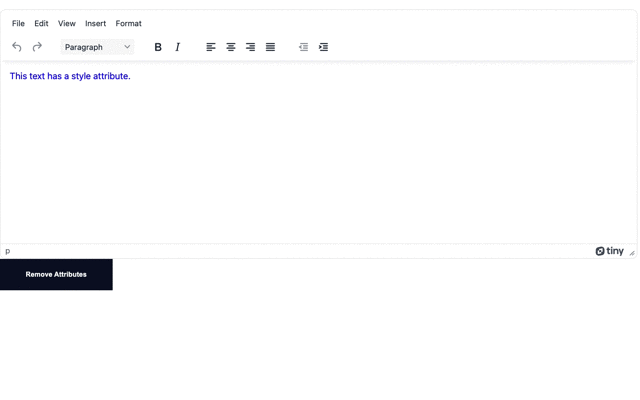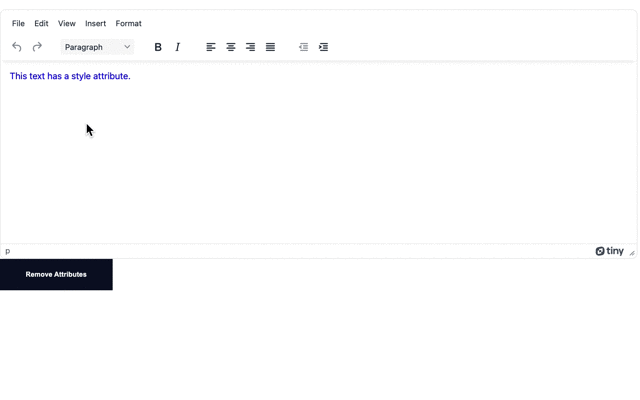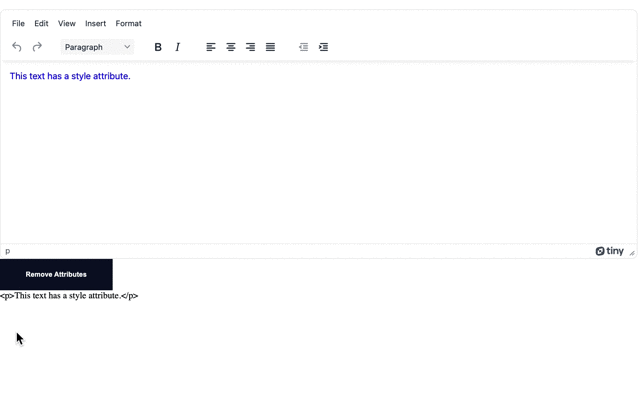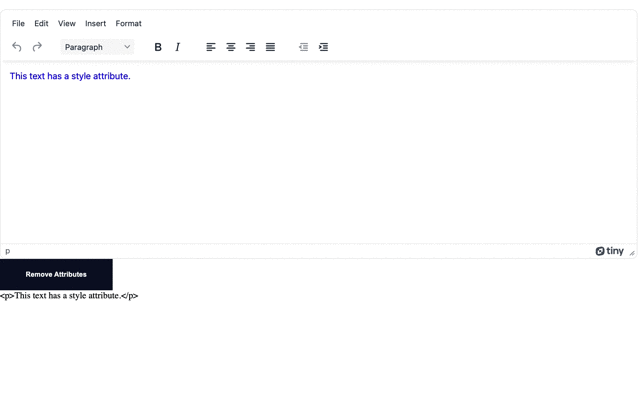
content = tinymce.activeEditor.getContent()
-
Add the .replace() function with the regular expression designed to detect a style tag:
<script>
function cleanTinyMCEContent() {
content = tinymce.activeEditor.getContent()
cleanContent = content.replace(/\s\w+="[^"]*"/g,'')Note: This pattern searches by using a negated character class combined with a possessive, or greedy, quantifier to find a match. This will match on All HTML attributes, including CSS selectors like classes and ids.
You could refine the regular expression by matching the character "s" before checking the content for word characters of any length: \s[s]\w+="[^"]*"/g. Be aware that this method adds a single, literal character to the expression pattern.
-
Use the document.createElement() method along with the document.createTextNode() and appenChild() to add the cleaned content to the newly created div. Get the current div element by it’s id, and then insert the clean content inside the div:
<script>
function cleanTinyMCEContent() {
content = tinymce.activeEditor.getContent()
cleanContent = content.replace(/\s\w+="[^"]*"/g,'')
newSection = document.createElement("div")
newContent = document.createTextNode(cleanContent)
newSection.appendChild(newContent)
currentSection = document.getElementById("newArea")
document.body.insertBefore(newSection, currentSection)
};As an alternative, you can output the content to the developer console in the browser.
-
Finally, set up a variable outside the function to listen for the click event on the button element, and to execute the function when the button click happens:
<script>
function cleanTinyMCEContent() {
content = tinymce.activeEditor.getContent()
cleanContent = content.replace(/\s\w+="[^"]*"/g,'')
newSection = document.createElement("div")
newContent = document.createTextNode(cleanContent)
newSection.appendChild(newContent)
currentSection = document.getElementById("newArea")
document.body.insertBefore(newSection, currentSection)
};
var buttonPublish = document.getElementById(buttonRemove);
buttonRemove.addEventListener('click', cleanTinyMCEContent, false);
</script>-
Save the changes, and load the index.html file in your browser to test out the cleaning process:
What other methods are available
When it comes to efforts and methods designed to remove style from css or other attributes from HTML, regular expressions are just one solution. You can also achieve the same methods as the .replace() JavaScript method in other languages, such as the PHP preg_replace() function.
On the subject of PHP, HTML purifier is a PHP library designed specifically for cleaning attributes from any HTML content received from different sources.
Another solution is more advanced regex, like Perl-enhanced regular expressions. Be aware that while they can parse more information, they can also run into trouble detecting specific attributes in HTML, and fall into the same edge case issues that affects standard regex.
Remember, the TinyMCE DOM Parser and Serializer methods can provide a more reliable solution to clearing style from HTML with TinyMCE.
If you have any further questions about TinyMCE APIs and HTML content, contact us, and we can help you to find the right solution. When you sign up for a FREE API key, you not only receive access to premium plugins for 14 days, but for that same period you also receive support for your project development.


